Descubriendo las Posibilidades en la Inteligencia Artificial- una Mirada en Profundidad. Parte I.
Introducción
En el capítulo l estudiamos que el aprendizaje automático, es un campo de la inteligencia artificial (IA) que implica:
El desarrollo de algoritmos y modelos estadísticos que permiten que los sistemas informáticos aprendan y hagan predicciones o decisiones basadas en datos sin estar programados explícitamente.
En el aprendizaje automático, los sistemas informáticos están capacitados para identificar patrones en grandes conjuntos de datos (big data) y hacer predicciones o decisiones basadas en estos patrones.
Los algoritmos aprenden iterativamente de los datos, ajustando sus parámetros en respuesta a la retroalimentación, hasta que puedan hacer predicciones o decisiones precisas.
Hay varios tipos de aprendizaje automático:
El aprendizaje supervisado.
El aprendizaje no supervisado.
El aprendizaje por refuerzo.
En este capítulo estudiaremos que es el aprendizaje automático supervisado (SML).
El aprendizaje automático supervisado:
Es un modelo donde se entrena un algoritmo en un conjunto de datos etiquetados para predecir o clasificar nuevos datos, el algoritmo aprende de:
Un conjunto de pares de entrada y salida, donde la entrada son los datos que se analizarán.
La salida es la respuesta correcta o la etiqueta asociada con esa entrada.
Durante el proceso de entrenamiento, el algoritmo ajusta sus parámetros internos para mapear (establecer una relación matemática) la entrada a la salida. El objetivo del aprendizaje supervisado es crear un modelo que pueda predecir con precisión la salida de datos de entrada nuevos e invisibles.
Hay dos tipos principales de aprendizaje supervisado:
Regresión.
Clasificación.
1. La regresión en el aprendizaje automático supervisado:
Es un tipo de tarea de aprendizaje automático en la que se entrena un modelo para predecir una variable de salida continua en función de las variables de entrada, dado un conjunto de ejemplos etiquetados. En otras palabras, el objetivo de la regresión es encontrar la mejor función matemática que asigne las características de entrada a un valor de salida continuo.
Las características de entrada también se denominan variables independientes o predictores.
La variable de salida también se denomina variable dependiente o variable de respuesta.
Los ejemplos etiquetados utilizados para entrenar el modelo consisten en pares de entrada y salida, donde la salida es un valor numérico continuo.
Hay varios algoritmos de regresión en el aprendizaje automático supervisado:
Regresión lineal:
El objetivo es predecir una variable numérica continua a partir de un conjunto de variables predictoras.

Ejemplos:
Predicción de precios de viviendas: El precio de una casa a partir de características como la ubicación, el tamaño, el número de habitaciones y baños, entre otras.
Predicción de ventas: Predecir las ventas de una empresa a partir de variables como el gasto en publicidad, el número de empleados, el precio del producto, entre otras.
Regresión polinomial:
Modela la relación entre una variable independiente X y una variable dependiente Y, cuando la relación entre ambas no es lineal. En lugar de ajustar una línea recta, como en la regresión lineal, la regresión polinomial ajusta una curva polinómica a los datos.

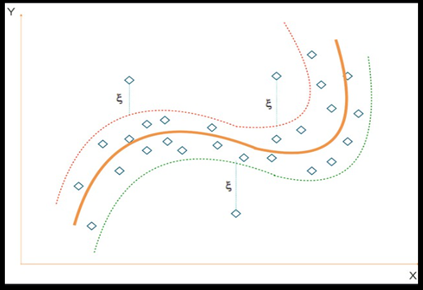
Regresión de vectores de soporte:
La regresión de vectores de soporte (SVR) es utilizada para predecir valores numéricos (continuos), en lugar de clasificar observaciones en categorías, como en la clasificación con vectores de soporte (SVM).
La SVR funciona encontrando una función lineal o no lineal que mejor se ajuste a los datos de entrenamiento, dentro de un margen de tolerancia o epsilon.
Regresión de bosque aleatorio:
Es utilizada para predecir valores numéricos (continuos), en la cual se construyen múltiples árboles de decisión (llamados bosques) y se combinan para mejorar la precisión de las predicciones.
Cada árbol se entrena en una submuestra aleatoria de los datos de entrenamiento y en un subconjunto aleatorio de las características.
Esto se conoce como muestreo de Bootstrap y se utiliza para reducir la varianza del modelo y evitar el sobreajuste.
Cada árbol produce una predicción y las predicciones de todos los árboles se combinan para producir la predicción final.

La elección de la técnica de regresión depende de la complejidad del problema, el tamaño y la calidad del conjunto de datos y otros factores.
Chat GPT
Es un modelo de lenguaje desarrollado por Open AI basado en la arquitectura GPT-3.5. Es capaz de generar respuestas similares a las humanas a las indicaciones del lenguaje natural y se puede utilizar para una amplia gama de aplicaciones, como:
Aplicaciones en la industria financiera:
Predicción de los precios de las acciones: la regresión se puede utilizar para predecir los precios de las acciones en función de los datos de precios históricos y otras variables relevantes, como las métricas de rendimiento de la empresa, los indicadores económicos y el sentimiento de las noticias.
Evaluación del riesgo crediticio: la regresión se puede utilizar para modelar la relación entre las características del prestatario y la solvencia, lo que permite a las instituciones financieras tomar decisiones crediticias más precisas y administrar el riesgo crediticio.
Detección de fraude: la regresión se puede utilizar para identificar patrones y anomalías en los datos de transacciones que pueden indicar actividad fraudulenta, como fraude con tarjetas de crédito o lavado de dinero.
Predicción de abandono de clientes: la regresión se puede usar para predecir la probabilidad de que un cliente deje de usar un producto o servicio financiero en particular, lo que permite a las instituciones retener a los clientes de manera proactiva y aumentar el valor de por vida del cliente.
Aplicaciones en Big Data:
Modelado predictivo: la regresión se puede utilizar para crear modelos predictivos para diversas aplicaciones, como la predicción de abandono de clientes, la previsión de ventas y la evaluación de riesgos. Con big data, los modelos de regresión se pueden entrenar en cantidades masivas de datos para hacer predicciones más precisas.
Sistemas de recomendación: la regresión se puede utilizar en técnicas de filtrado colaborativo para crear sistemas de recomendación, que se utilizan para sugerir productos o servicios a los clientes en función de su comportamiento anterior. En big data, los modelos de regresión se pueden entrenar en conjuntos de datos masivos de interacciones de usuarios para proporcionar recomendaciones más personalizadas.
Reconocimiento de imagen y voz: la regresión se puede utilizar en aplicaciones de procesamiento de lenguaje natural y visión artificial para el reconocimiento de imagen y voz. Por ejemplo, la regresión se puede utilizar para asignar características acústicas a fonemas en el reconocimiento de voz o para clasificar imágenes según las características visuales.
Detección de anomalías: la regresión se puede utilizar para detectar anomalías en grandes conjuntos de datos, como la detección de fraudes en transacciones financieras o la detección de intrusiones en la red en ciberseguridad. Los modelos de regresión se pueden entrenar en datos históricos para identificar patrones que están fuera del comportamiento normal.
Aplicaciones en la industria de bienes raíces:
Valoración de la propiedad: la regresión se puede utilizar para predecir el valor de una propiedad en función de varias características, como la ubicación, el tamaño, la cantidad de habitaciones y las comodidades. Con grandes conjuntos de datos, los modelos de regresión se pueden entrenar para hacer predicciones más precisas y proporcionar información sobre los impulsores del valor de la propiedad.
Predicción de alquiler: la regresión se puede utilizar para predecir los precios de alquiler de propiedades en función de características similares, como la ubicación y las comodidades. Con big data, los modelos de regresión se pueden entrenar en grandes conjuntos de datos de precios de alquiler para proporcionar predicciones e información más precisas sobre las tendencias del mercado de alquiler.
Análisis de inversión: la regresión se puede utilizar para analizar el rendimiento histórico de las inversiones inmobiliarias e identificar tendencias y patrones que pueden informar las decisiones de inversión. Por ejemplo, la regresión se puede utilizar para modelar la relación entre los valores de las propiedades y los indicadores económicos, como las tasas de interés y el PIB.
Evaluación de riesgos: la regresión se puede utilizar para modelar la relación entre las características de la propiedad y los factores de riesgo, como los desastres naturales o las tasas de criminalidad. Con big data, los modelos de regresión se pueden entrenar en grandes conjuntos de datos de riesgos históricos para identificar áreas de alto riesgo e informar estrategias de gestión de riesgos.
Observación final:
En general, la regresión en el aprendizaje automático puede proporcionar información valiosa sobre las tendencias de los sectores industriales lo que permite tomar decisiones más informadas sobre inversiones y gestión de riesgos.