Uncovering the Possibilities in Artificial Intelligence- an in-Depth Look. Part I
Introduction
In Chapter I we studied that machine learning is a field of artificial intelligence (AI) that involves:
The development of algorithms and statistical models enables computer systems to learn and make predictions or decisions based on data without being explicitly programmed.
In machine learning, computer systems are trained to identify patterns in large data sets (big data) and make predictions or decisions based on these patterns.
Algorithms iteratively learn from the data, adjusting their parameters in response to feedback, until they can make accurate predictions or decisions.
There are several types of machine learning:
Supervised learning.
Unsupervised learning.
Reinforcement learning.
In this chapter, we will study what is supervised machine learning (SML).
Supervised machine learning:
A model in which an algorithm is trained on a set of labeled data to predict or classify new data, from which the algorithm learns:
A set of input and output pairs, where the input is the data to be analyzed.
The output is the correct answer or label associated with that input.
During the training process, the algorithm adjusts its internal parameters to map (establish a mathematical relationship) the input to the output. The goal of supervised learning is to create a model that can accurately predict the output of new and unknown input data.
There are two main types of supervised learning:
Regression.
Classification.
1. Regression in supervised machine learning:
It is a type of machine learning task in which a model is trained to predict a continuous output variable based on input variables, given a set of labeled examples. In other words, the goal of regression is to find the best mathematical function that maps input features to a continuous output value.
The input characteristics are also called independent variables or predictors.
The output variable is also called the dependent variable or response variable.
The labeled examples used to train the model consist of input-output pairs, where the output is a continuous numerical value.
There are several regression algorithms in supervised machine learning:
Linear regression:
The objective is to predict a continuous numerical variable from a set of predictor variables.
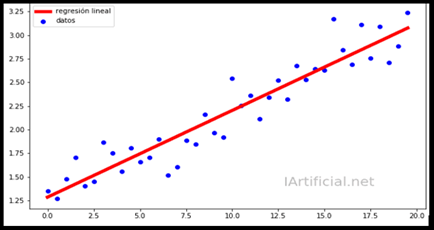
Examples:
Housing price prediction: Pricing of a home based on characteristics such as location, size, number of bedrooms and bathrooms, among others.
Sales prediction: Predicting a company's sales based on variables such as advertising spending, number of employees, product price, among others.
Polynomial regression:
It models the relationship between an independent variable X and a dependent variable Y when the relationship between the two is not linear. Instead of fitting a straight line, as in linear regression, polynomial regression fits a polynomial curve to the data.
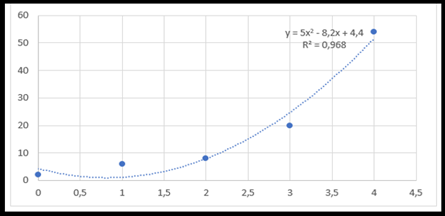
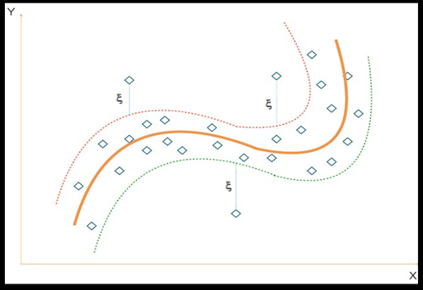
Support vector regression:
Support vector regression (SVR) is used to predict numerical (continuous) values, rather than classifying observations into categories, as in support vector classification (SVM).
SVR works by finding a linear or non-linear function that best fits the training data, within a tolerance, or epsilon.
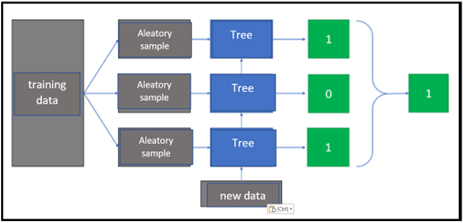
Random Forest Regression:
It is used to predict numerical (continuous) values, in which multiple decision trees (called forests) are constructed and combined to improve prediction accuracy.
Each tree is trained with a random subsample of the training data and a random subset of the features.
This is known as bootstrap sampling and is used to reduce model variance and avoid overfitting.
Each tree produces a prediction, and the predictions from all the trees are combined to produce the final prediction.
The choice of regression technique depends on the complexity of the problem, the size and quality of the data set and other factors.
GPT-chat
It is a linguistic model developed by Open AI based on the GPT-3.5 architecture. It is capable of generating human-like responses to natural language questions and can be used for a wide range of applications, such as:
Applications in the financial industry:
Stock Price Prediction: Regression can be used to predict stock prices based on historical price data and other relevant variables, such as company performance metrics, economic indicators and stock sentiment. News.
Credit risk assessment: Regression can be used to model the relationship between borrower characteristics and creditworthiness, enabling financial institutions to make more accurate credit decisions and manage credit risk.
Fraud detection: Regression can be used to identify patterns and anomalies in transaction data that may indicate fraudulent activity, such as credit card fraud or money laundering.
Customer churn prediction: Regression can be used to predict the likelihood that a customer will stop using a particular financial product or service, allowing institutions to proactively retain customers and increase profitability. Customer lifetime.
Big Data Applications:
Predictive Modeling: Regression can be used to create predictive models for a variety of applications, such as churn prediction, sales forecasting, and risk assessment. With big data, regression models can be trained on massive amounts of data to make more accurate predictions.
Recommender Systems: Regression can be used in collaborative filtering techniques to create recommender systems, which are used to suggest products or services to customers based on past behavior. In big data, regression models can be trained on massive data sets of user interactions to provide more personalized recommendations.
Image and speech recognition: Regression can be used in natural language processing and computer vision applications for image and speech recognition. For example, regression can be used to assign acoustic features to phonemes in speech recognition, or to classify images based on visual features.
Anomaly detection: Regression can be used to detect anomalies in large data sets, such as detecting fraud in financial transactions or detecting intrusions in cyber security networks. Regression models can be trained on historical data to identify patterns that depart from normal behavior.
Applications in the real estate industry:
Property valuation: Regression can be used to predict the value of a property based on various characteristics, such as location, size, number of rooms and amenities. With large data sets, regression models can be trained to make more accurate predictions and provide insight into the factors that drive property values.
Rent Prediction: Regression can be used to predict rental prices of properties based on similar characteristics, such as location and amenities. With big data, regression models can be trained on large rental price data sets to provide more accurate predictions and insights into rental market trends.
Investment analysis: Regression can be used to analyze the historical performance of real estate investments and identify trends and patterns that can inform investment decisions. For example, regression can be used to model the relationship between real estate values and economic indicators such as interest rates and GDP.
Risk Assessment: Regression can be used to model the relationship between real estate characteristics and risk factors, such as natural disasters or crime rates. With big data, regression models can be trained on large historical risk data sets to identify high-risk areas and inform risk management strategies.
Closing remark:
Overall, machine learning regression can provide valuable insights into industry sector trends, enabling more informed investment and risk management decisions.